4. 快取計算結果
第2與3項只修正 bug 但對效能沒有直接改善,以目前的觀測結果,程式向系統申請的記憶體用量還有點高(350M左右),
接著來檢查 GC 與 heap 狀況看哪些物件申請了這些記憶體
用 GOGCTRACE=1 讓 GO runtime 把 gclog 印出來,將印出的訊息傳給 log2csv 轉成 csv 檔案
$ GOGCTRACE=1 ./gb -c 100 -n 200000 -k http://localhost/10k.dat 2>&1 | log2csv -t -o gc.csv
unixtime,numgc,nproc,mark,sweep,cleanup,heap0,heap1,obj0,obj1,nmalloc,nfree,nhandoff,nhandoffcnt,nsteal,nstealcnt,nprocyield,nosyield,nsleep
1366278874.698135,1,1,0,0,0,0,0,24,26,27,1,0,0,0,0,0,0,0
1366278874.701761,2,2,1,0,0,2,2,608,518,642,124,0,0,5,31,22,4,0
1366278874.707143,3,2,4,0,0,4,4,993,985,1118,133,0,0,2,41,22,15,6
1366278874.725975,4,2,6,0,0,9,9,36182,36148,36317,169,6,187,2,78,70,24,17
1366278874.767119,5,2,13,0,0,18,18,113518,113518,113688,170,3,87,2,301,42,23,21
1366278874.837911,6,2,16,1,0,37,37,268246,268246,268417,171,4,93,2,48,54,20,11
1366278874.982132,7,2,35,2,0,75,75,577694,577694,577866,172,6,287,2,306,42,23,31
1366278875.267363,8,2,67,5,1,150,150,1196615,1196615,1196788,173,5,182,2,2063,32,23,11
1366278877.850924,9,2,64,35,8,301,154,2212070,1183694,2284625,1100931,8,502,13,16101,16,14,2
1366278879.561168,10,2,63,23,5,309,147,2233288,1119515,3411483,2291968,2,47,4,10961,32,16,13
1366278881.097839,11,2,70,40,2,294,139,2121182,1054221,4486980,3432759,2,17,4,17879,32,5,0
1366278882.543087,12,2,57,24,7,278,131,2000935,993438,5503542,4510104,1,2,3,9999,19,12,12
1366278883.873273,13,2,48,25,2,262,124,1888388,935583,6464524,5528941,3,152,2,10759,26,22,2
(略)
gc.csv
再用 gnuplot 將 csv 檔案裡的數據繪制成圖表 gnuplot-heap.p
$ gnuplot gnuplot-heap.p
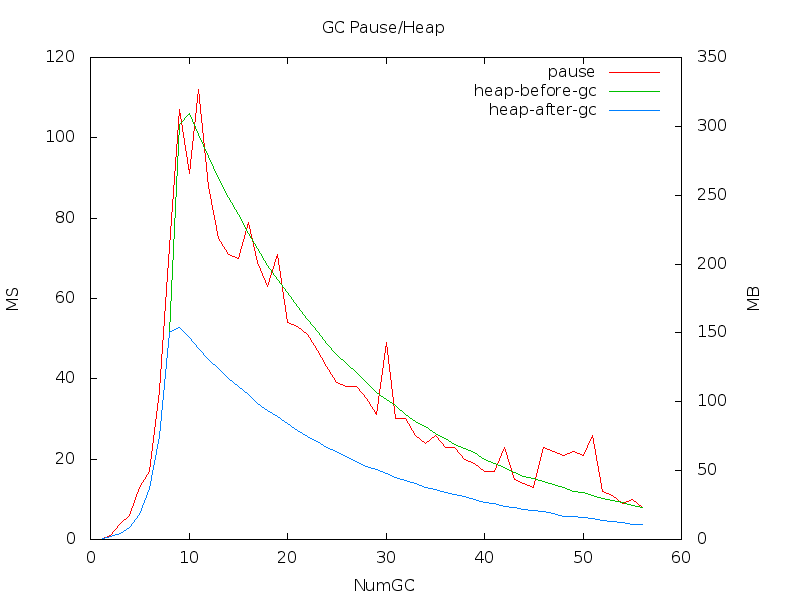
看起來是程式開始申請了過量的記憶體,GC 清空後 runtime 也沒把多餘的空間再還給作業系統,
再分析 gc.csv 後找到大量申請時間約在第6-10次gc, 於程式啟動後第5秒的時候達到最大值
為了要找出開始大量申請空間的物件,下面的程式在第1秒與第7秒各 dump 一次 heap
func main() {
SetMemProfileRate(1)
go func() {
time.Sleep(time.Duration(1) * time.Second)
DumpHeap()
time.Sleep(time.Duration(6) * time.Second)
DumpHeap()
}()
// ignored
PrintGCSummary()
}
$ ./gb -c 100 -n 200000 http://localhost/10k.dat
(略)
NumGC:56 Pause:113.57ms Pause(Avg):425.33ms Overhead:30.54% Alloc:22.53M Sys:662.14M Alloc(Rate):43.24M/s Histogram:996.58ms 1.07s 1.07s
在 go tool pprof 加上 --base 顯示兩個 profile 相減後的數據
$ go tool pprof ./gb --base heap-19221-1.pprof heap-19221-2.pprof
(pprof) top
Total: 74.3 MB
35.6 47.9% 47.9% 35.6 47.9% net/textproto.MIMEHeader.Set
26.3 35.4% 83.3% 37.1 50.0% net/http.NewRequest
10.8 14.6% 97.9% 10.8 14.6% net/url.parse
1.5 2.1% 100.0% 1.5 2.1% net/textproto.MIMEHeader.Add
0.0 0.0% 100.0% 0.0 0.0% resizefintab
0.0 0.0% 100.0% 0.0 0.0% itab
0.0 0.0% 100.0% 0.0 0.0% os.NewFile
0.0 0.0% 100.0% 0.0 0.0% concatstring
(pprof) top -cum
Total: 74.3 MB
0.0 0.0% 0.0% 74.3 100.0% gosched0
0.0 0.0% 0.0% 74.3 100.0% main.(*Benchmark).Run
0.0 0.0% 0.0% 74.3 100.0% main.NewHttpRequest
0.0 0.0% 0.0% 74.3 100.0% main.main
0.0 0.0% 0.0% 74.3 100.0% main.startBenchmark
0.0 0.0% 0.0% 74.3 100.0% runtime.main
26.3 35.4% 35.4% 37.1 50.0% net/http.NewRequest
0.0 0.0% 35.4% 35.6 47.9% net/http.Header.Set
35.6 47.9% 83.3% 35.6 47.9% net/textproto.MIMEHeader.Set
0.0 0.0% 83.3% 10.8 14.6% net/url.Parse
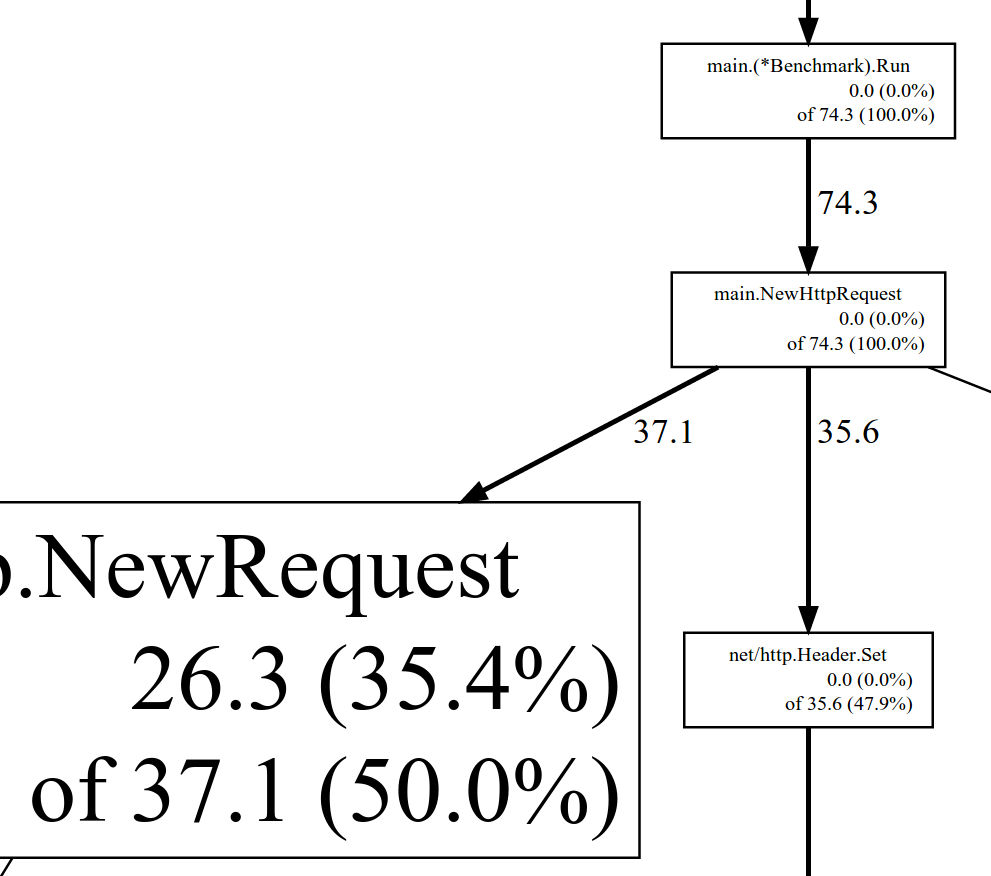
比較兩個 heap 過後,總共增加了 74.3 MB,從top -cum顯示這 74.3MB 100.0% 是 main.(*Benchmark).Run 底下產生的
(pprof) web main.\(\*Benchmark\).Run
 SVG File
SVG File
(pprof) list main.\(\*Benchmark\).Run
Total: 74.3 MB
ROUTINE ====================== main.(*Benchmark).Run in /home/brandon/workspaces/go/src/bench/gb/benchmark.go
0.0 74.3 Total MB (flat / cumulative)
. . 27: monitor := NewMonitor(config, collector, start, stop)
. . 28:
. . 29: return &Benchmark{config, collector, monitor, start, stop}
. . 30: }
. . 31:
---
. . 32: func (b *Benchmark) Run() {
. . 33:
. . 34: go b.monitor.Run()
. . 35:
. . 36: jobs := make(chan *http.Request, b.config.requests)
. . 37:
. . 38: for i := 0; i < b.config.concurrency; i++ {
. . 39: go NewHttpWorker(b.config, jobs, b.collector, b.start, b.stop).Run()
. . 40: }
. . 41:
. . 42: for i := 0; i < b.config.requests; i++ {
. 74.3 43: newRequest, _ := NewHttpRequest(b.config)
. . 44: jobs <- newRequest
. . 45: }
. . 46: close(jobs)
. . 47:
. . 48: close(b.start)
. . 49: <-b.stop
. . 50: }
---
(pprof)
main.(*Benchmark).Run 的 L:43 NewHttpRequest 增加了 74.3 MB 的記憶體,從程式行為來分析,問題是L:42的迴圈在一開始就產生了所有 NewHttpRequest,另一個是 NewHttpRequest 是個昂貴的操作為了建立 http.NewRequest 衍生使用了 textproto.MIMEHeader.Set 與 net/url.parse
優化方法:複製 httpRequest 結果避免同樣的計算與空間浪費
func (b *Benchmark) Run() {
go b.monitor.Run()
jobs := make(chan *http.Request, b.config.requests)
for i := 0; i < b.config.concurrency; i++ {
go NewHttpWorker(b.config, jobs, b.collector, b.start, b.stop).Run()
}
base, _ := NewHttpRequest(b.config)
for i := 0; i < b.config.requests; i++ {
newRequest := CopyHttpRequest(b.config, base)
jobs <- newRequest
}
close(jobs)
close(b.start)
<-b.stop
}
func CopyHttpRequest(config *Config, request *http.Request) *http.Request {
if config.method == "POST" || config.method == "PUT" {
newRequest := *request
if newRequest.Body != nil {
newRequest.Body = ioutil.NopCloser(bytes.NewReader(config.bodyContent))
}
return &newRequest
} else {
return request
}
}
執行結果
$ ./gb -c 100 -n 200000 -k http://localhost/10k.dat
(略)
Document Path: /10k.dat
Document Length: 10240 bytes
Concurrency Level: 100
Time taken for tests: 12.14 seconds
Complete requests: 200000
Failed requests: 0
HTML transferred: 2048000000 bytes
Requests per second: 16471.31 [#/sec] (mean)
Time per request: 6.071 [ms] (mean)
Time per request: 0.061 [ms] (mean, across all concurrent requests)
HTML Transfer rate: 164713.14 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Total: 0 0 3.50 4 38
Percentage of the requests served within a certain time (ms)
50% 4
66% 5
75% 7
80% 7
90% 10
95% 12
98% 14
99% 17
100% 38 (longest request)
NumGC:49 Pause:6.15ms Pause(Avg):7.52ms Overhead:3.00% Alloc:18.19M Sys:284.25M Alloc(Rate):64.70M/s Histogram:10.50ms 13.11ms 13.11ms
$ echo " PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND"; top -d 1 -b | grep gb
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9529 brandon 20 0 732m 20m 2860 S 29.7 0.1 0:00.30 gb
9529 brandon 20 0 942m 23m 2864 S 103.6 0.1 0:01.35 gb
9529 brandon 20 0 1016m 24m 2864 S 105.1 0.2 0:02.41 gb
9529 brandon 20 0 1016m 24m 2864 S 103.5 0.2 0:03.46 gb
9529 brandon 20 0 1088m 25m 2864 S 104.1 0.2 0:04.51 gb
9529 brandon 20 0 1088m 25m 2864 S 104.0 0.2 0:05.56 gb
9529 brandon 20 0 1088m 26m 2864 S 102.2 0.2 0:06.59 gb
9529 brandon 20 0 1088m 26m 2864 S 103.8 0.2 0:07.64 gb
9529 brandon 20 0 1160m 26m 2864 S 104.2 0.2 0:08.69 gb
9529 brandon 20 0 1160m 26m 2864 S 105.1 0.2 0:09.75 gb
9529 brandon 20 0 1160m 27m 2864 S 103.2 0.2 0:10.79 gb
9529 brandon 20 0 1160m 27m 2864 S 103.1 0.2 0:11.83 gb
向系統申請記憶體終於在這次測試裡降下來(25MB vs 350MB),平均 GC 停頓時間也降低(7.52ms vs 40.91ms)
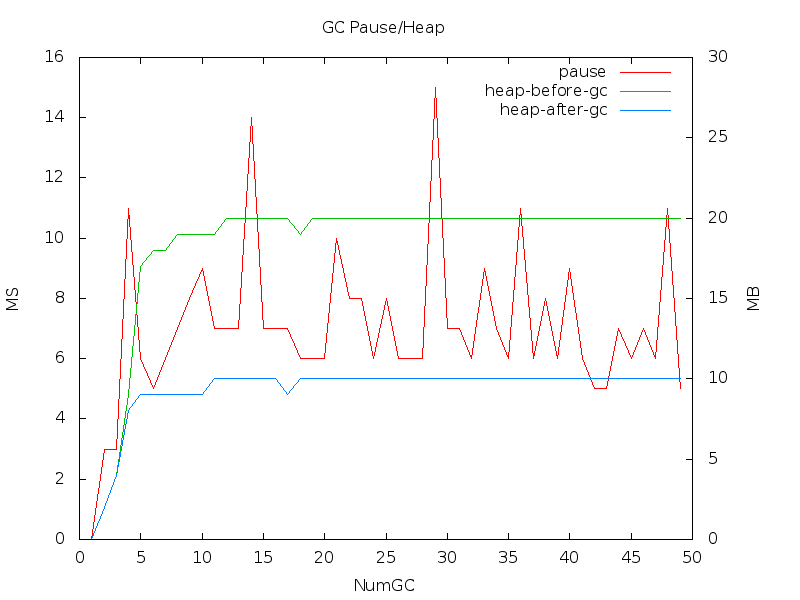
gc2.csv











{kind=link}
{kind=link}
{kind=link}